Failover / Hyper-V Clustering
Stretch Cluster – Hyper-Converged Cluster – Storage Spaces Direct (S2D) – Windows Server 2025
Zielgruppe:
Das Seminar richtet sich an Serveradministratoren.
Voraussetzungen:
Erfahrung mit Active Directory und gute Kenntnisse in Windows 20xx und Netzwerk sind von Vorteil, jedoch keine Bedingung.
Zertifikat:
Nach erfolgreicher Teilnahme erhalten die Kursteilnehmer ein Zertifikat von NT Systems.
Kursdokumentation:
Die digitale Kursdokumentation erhalten die Teilnehmer einen Werktag vor Kursbeginn. Diese ist im Kurspreis inbegriffen. Auf Wunsch kann gegen einen Aufpreis von 300,– € zzgl. MwSt. zusätzlich eine Printversion dazugebucht werden.
Schulungszeiten:
Tag 1: 09:00–17:00 Uhr / Tag 2–4: 08:30–17:00 Uhr / Tag 5: 08:30–13:00 Uhr
Failover / Hyper-V Clustering Intensivkurs im Detail
Die größte Neuerung im Bereich Failover- und Hyper-V-Clustering ist das Feature Cluster Set. Es ermöglicht, mehrere kleinere Hyper-V-Cluster, sogenannte Building Blocks, zu einem großen, lose gekoppelten Cluster-Set zusammenzuschließen. Ein solcher Building Block besteht aus einem eigenständigen Hyper-Converged Cluster mit jeweils vier Nodes und eigenem Storage Spaces Direct (S2D). Ziel des Cluster Sets ist es, eine zentrale Verwaltung einer großen Anzahl von VMs zu gewährleisten, die die Ressourcen des gesamten Sets gemeinsam nutzen. VMs können dabei sogar über die Clustergrenzen hinweg auf andere Nodes migriert werden. Ähnlich dem Konzept von DFS-N bietet das Cluster Set einen übergeordneten Zugriffspunkt: Den globalen Namespace Referral Scale-Out File-Server (SOFS). Über diesen können VMs auf einen oder mehrere Infrastructure SOFS zugreifen, die einen gemeinsamen Root Namespace bereitstellen.
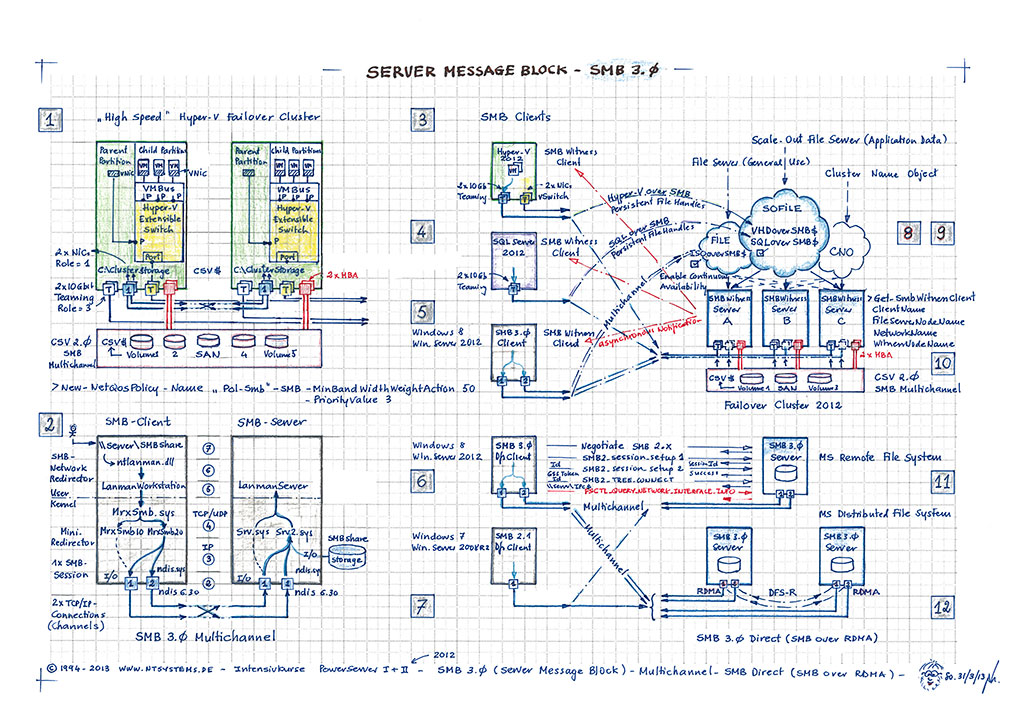
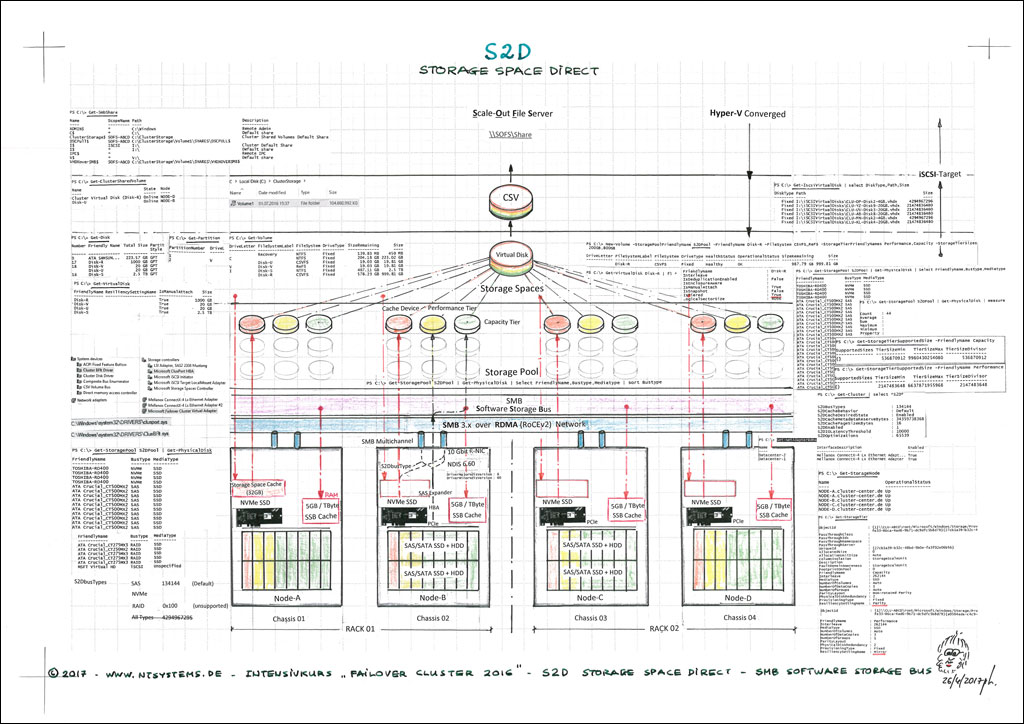
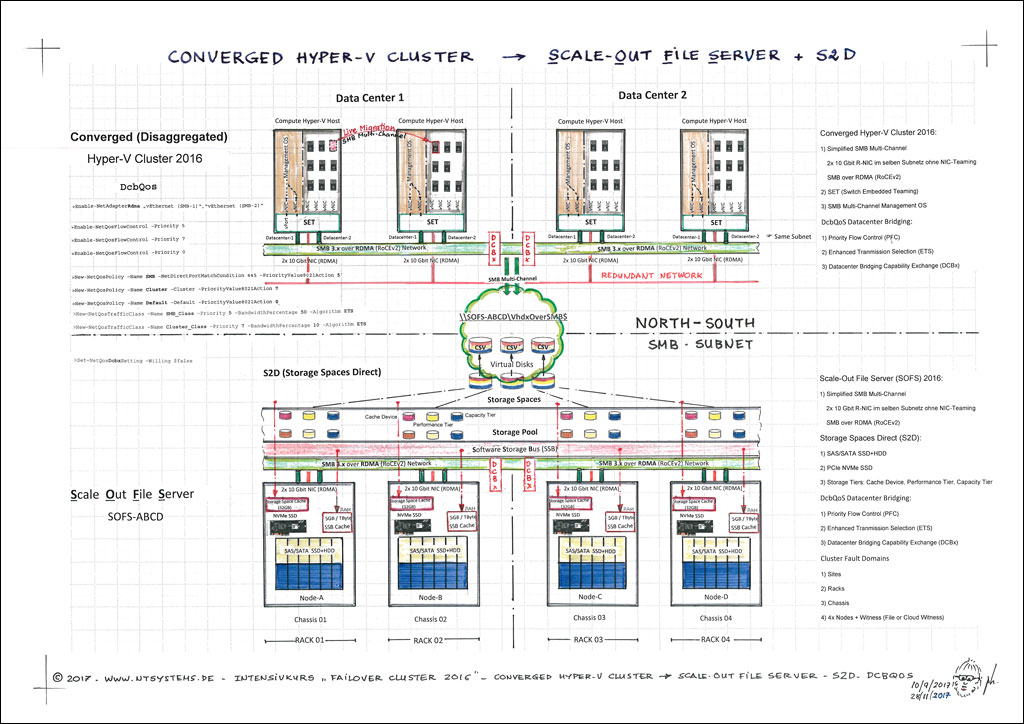
Neben den physischen Windows Server-Varianten (Full und Server Core) wird der Fokus auf Hyper-Converged Cluster mit Storage Spaces Direct (S2D) weiter verstärkt. Ein Hyper-Converged Cluster nutzt lokal verfügbare, hochverfügbare S2D-Speicher, um die VMs direkt innerhalb desselben Clusters zu hosten. Im Gegensatz dazu setzt ein Compute Hyper-V Cluster auf Remote Storage, der über SMB over RDMA auf einem Scale-Out File Server (SOFS) Cluster bereitgestellt wird – ein Thema, das ebenfalls im Kurs behandelt wird.
Im Kurs wird die Konfiguration von Storage Spaces Direct (S2D) mit hochperformanten 10 GBit RoCEv2 R-NICs (RDMA) und SMB-Multichannel praktisch umgesetzt. Dank der RDMA-Unterstützung und der Funktionen Simplified SMB Multichannel sowie Multi-NICs lässt sich ein leistungsstarker Cluster mit lediglich 2x 10 GBit/s P-NICs aufbauen. Diese beiden Netzwerkkarten übernehmen alle Netzwerkaufgaben (außer iSCSI) und können dabei im selben Subnetz betrieben werden. Für Hyper-V-Cluster wird anstelle des klassischen NIC-Teaming Switch Embedded Teaming (SET) eingesetzt, das bis zu 8 P-NICs unterstützen kann. Dies beschleunigt Management-Aufgaben wie Live Migration over SMB erheblich. Auch die VMs profitieren bei korrekter Konfiguration von SMB Multichannel over RDMA, was die Netzwerkperformance weiter steigert. Storage Spaces Direct (S2D) erlaubt es, einen Software-Defined Storage (SDS) aufzubauen, ohne auf teure Hardware-SANs angewiesen zu sein.
Hyper-V unterstützt die virtuellen NUMA-Topologie, um die Leistung von VMs mit großem Arbeitsspeicher zu optimieren. Dynamic Memory steigert die Konsolidierung und Neustartzuverlässigkeit, was besonders in VDI-Pools zu Kostensenkungen führt. Der Dynamic Processor Compatibility Mode sorgt für ein einheitliches Prozessorfunktionsset über alle Cluster-Hosts hinweg. GPU-Partitionierung ermöglicht das Teilen einer physischen GPU zwischen mehreren VMs, sodass jede VM nur einen Bruchteil der GPU nutzt. Schließlich bietet Storage Spaces Direct (S2D) Site-Awareness mit Stretch Cluster in Windows Server 2025.
Hier sind die Highlights von unserem Failover / Hyper-V Clustering Kurs:
- Multi-NIC Cluster Network & Simplified SMB Multichannel
- 10 GBit und 100 GBit P-NIC für iWARP (Internet Wide Area RDMA Protocol) / RoCEv2 (RDMA over Converged Ethernet)
- RoCEv2 benötigt QoS (Quality Of Service) und DCB (Data Center Bridging) mit PFC (Priority Flow Control) und ETS (Enhanced Transmission Selection)
- Network ATC
- Accelerated Networking
- Storage Spaces Direct (S2D) over SMB 3.1.1
- Storage Replication (SR) over SMB 3.1.1
- SOFS (Scale-Out File Server) in Kombination mit Storage Spaces Direct (S2D) und R-NIC
- Hyper-V SET (Switch Embedded Teaming) mit P-NIC und SR-IOV
- Hyper-V Cluster Full & Server Core
- Hyper-V Node Fairness und VM Resiliency Workflow
- Hyper-V vNUMA, Dynamic Memory, Dynamic Processor Compatibility
- Converged (Compute) oder Hyper-Converged Cluster
- Fault Domains und Site-awareness Failover Cluster
- Stretch Cluster mit SAN oder S2D
- Troubleshooting: Cluster Performance History, Cluster Log
- ClusterSet – Infrastructure SOFS, Root Namespace Referral SOFS, Logical Fault Domain und Availability Set
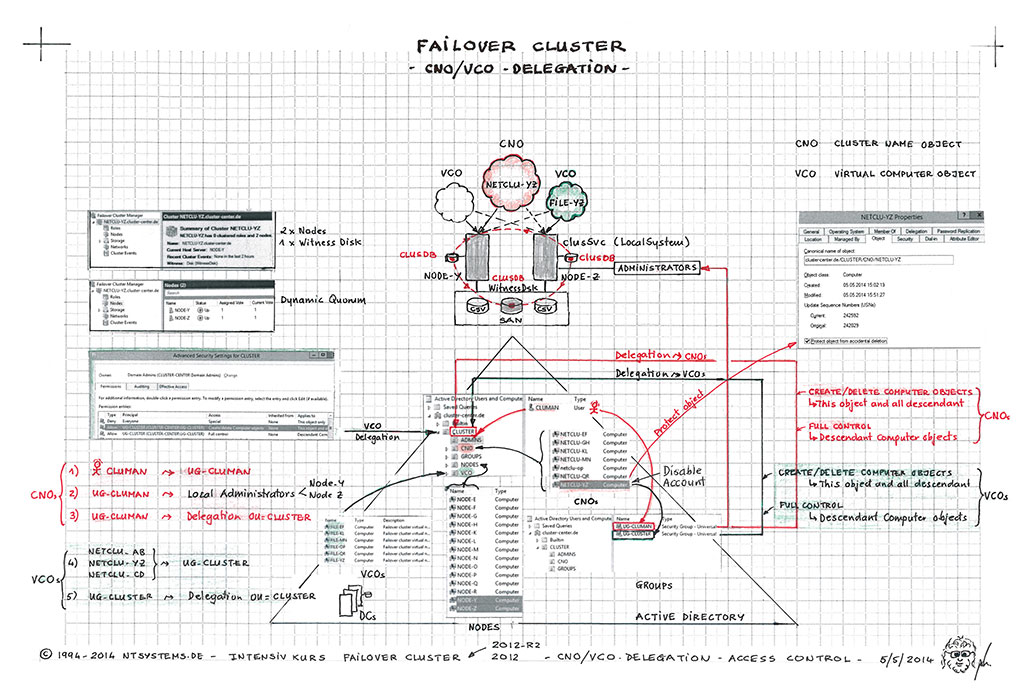
Zunächst lernen Sie Windows Failover Cluster als NICHT multimasterfähig (Share-Nothing-Prinzip). Das Quorum des gesamten Clusters wird durch eine gemeinsame Witness Disk (Shared Disk) als Majority Node Set gebildet. Jede Cluster-Ressource kann zu jedem Zeitpunkt nur einem Knoten zugeordnet sein, ähnlich wie bei einem traditionellen File Server Cluster, das mit einem SAN arbeitet.
S2D und SR nutzen das erweiterte SMB 3.1.1-Protokoll, das Basis für Funktionen wie Live Migration, CSV und SMB Multi-Channel. In Kombination mit 10 Gbit/s RDMA-fähigen Netzwerkkarten und NDIS 6.60 ermöglicht es echtes High-Speed Networking. RDMA (Remote Direct Memory Access) transportiert Daten direkt aus dem User Mode über das Netzwerk, ohne den Kernel zu belasten. Für RDMA sind ein verlustfreies Netzwerk mit hoher Bandbreite (High Bandwidth), niedriger Latenz (Low Latency), eine hohe Priorität durch PFC (Priority Flow Control) und die benötigte Bandbreite durch ETS (Enhanced Transmission Selection) erforderlich, was durch QoS und DCB (Data Center Bridging) unterstützt wird. Dies ermöglicht höhere Durchsatzraten, mit 1 bis 2 GByte/s bei 10 Gbit/s-Netzwerkkarten. Ein RDMA-fähiges 10 Gbit/s-Netzwerk ist daher essenziell für effiziente SMB-Transporte. SMB Direct (SMB over RDMA) und Storage Spaces Direct nutzen beide RDMA für optimierte Performance.
Der Scale-Out File Server (SOFS) gewinnt durch SMB 3.1.1 und Storage Spaces Direct (S2D) weiter an Bedeutung und bildet das zentrale Element im Microsoft Software Defined Storage (SDS)-Ansatz innerhalb eines Software Defined Data Center (SDDC). Anwendungen wie Hyper-V oder SQL Server können ihre VHDX-Dateien oder Datenbanken über SMB Direct (SMB over RDMA) direkt und effizient über Ethernet auf einem hochverfügbaren SOFS speichern, der auf kostengünstigen, lokalen Festplatten basiert. Dadurch entfällt die Notwendigkeit eines klassischen SANs. In einer Enterprise-Umgebung wird empfohlen, die Datenspeicherung von den Hyper-V-Hosts bzw. -Clustern zu trennen. Ein Converged (Compute) Hyper-V speichert seine VMs nicht lokal, sondern nutzt SMB 3.1.1, um die Daten auf einem Scale-Out File Server (SOFS) Cluster abzulegen. Dieser kann auch als Speicherort für andere Anwendungen wie den SQL Server dienen.
Im Kurs setzen wir den neuen Hyper-V Cluster (verfügbar als Full- und Core-Version) mit Switch Embedded Teaming (SET) um, das aus bis zu 8 RDMA-fähigen Netzwerkkarten (R-NICs) bestehen kann. Je nach Einsatz wird der Cluster als Compute Cluster oder Hyper-Converged Cluster genutzt und stellt den VMs Ressourcen wie CPU, Arbeitsspeicher, Netzwerk und Speicher zur Verfügung. Die VHDX-Dateien und Konfigurationsdaten der VMs werden über SMB 3.1.1 auf einem Infrastructure Scale-Out File Server (SOFS) abgelegt. Jeder Node des SOFS ist mit 2x 10 GBit/s Netzwerkanbindung ausgestattet und unterstützt SMB Multichannel, um eine hohe Leistung zu gewährleisten. Als Speicherlösung kommt Storage Spaces Direct (S2D) zum Einsatz. Dabei stellt jeder Cluster-Node mehrere lokale Festplatten für den gemeinsamen Storage Pool bereit, wodurch eine hochverfügbare und leistungsstarke Speicherinfrastruktur geschaffen wird.
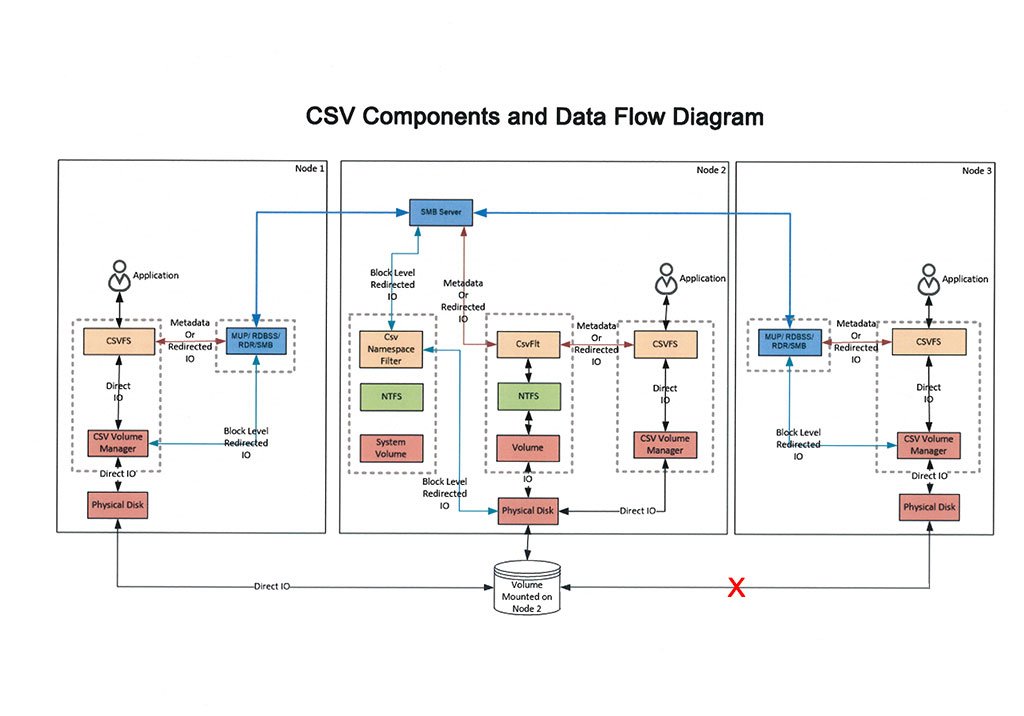
Das neue Fehlertoleranz-Konzept der Fault Domain, wie es aus Azure bekannt ist, zielt darauf ab, Single Points of Failure im Cluster zu vermeiden. Dazu werden Clusternodes über mehrere Sites, Racks, Chassis und Nodes verteilt. Diese Top-Down-Fault-Domain-Struktur mit vier Ebenen ist Voraussetzung für Features wie S2D und Storage Replica (SR). Bei einem Failover wird bevorzugt ein anderer Node innerhalb derselben Site genutzt, sofern diese mindestens zwei Nodes umfasst und als Fault Domain definiert ist (Failover Affinity). Dank Storage Affinity zieht eine VM bei einem Host-Ausfall einen Node in derselben Site vor. Auch die Auswahl des neuen CSV Coordinators berücksichtigt die Site Fault Domain.
Eine Preferred Site für das Dynamic Quorum kann clusterweit definiert werden und ist verwandt, aber nicht gleichzusetzen mit der Site Fault Domain. Bei einem Netzwerkausfall zwischen zwei Datacentern mit jeweils 2 Nodes passt das Quorum die Stimmenverteilung automatisch an. Die Preferred Site erhält dabei eine Stimme mehr als die andere Site, wodurch der Cluster bevorzugt in dieser Site weiterarbeitet.
Hyper-V bietet zahlreiche Funktionen, die die Virtualisierungsverwaltung erleichtern. Dazu gehört die VM Start Order, mit der Abhängigkeiten zwischen VMs definiert werden können. So lassen sich beispielsweise Domain Controller (DCs) einer Cluster Group Set-Gruppe zuweisen, während Anwendungs-VMs in einer anderen Gruppe organisiert werden. In diesem Szenario können die Anwendungs-VMs erst gestartet werden, wenn die DCs bereits in Betrieb sind. Dieses Feature stellt sicher, dass kritische Infrastrukturkomponenten in der richtigen Reihenfolge verfügbar sind, was die Stabilität und Verfügbarkeit des Systems verbessert.
Mit dem Feature Failover Cluster Node Fairness für Hyper-V kann über den Parameter AutoBalancerLevel (Low, Medium, High) auf Clusterebene festgelegt werden, wie aggressiv die automatische Lastverteilung der VMs auf Hyper-V Clusternodes erfolgt. Standardmäßig (auf Low) werden VMs erst dann auf andere Clusternodes verschoben, wenn die CPU– und Memory-Nutzung des Hyper-V Hosts 80% überschreiten.
Das Feature Virtual Machine Compute Resiliency steuert das Verhalten von Hyper-V Hosts und deren VMs bei Fehlern. Es gibt drei Zustände: Unmonitored State für VMs und Isolated sowie Quarantine State für Hosts. Ein Host geht in Quarantäne, wenn er dreimal innerhalb einer Stunde unsauber den Cluster verlässt (z. B. durch Überschreiten des Heartbeat Thresholds). In diesem Fall werden die VMs auf andere Clusternodes verschoben. Dies kann auch mit Fault Domains kombiniert werden.
Hyper-V führt die Unterstützung für die Projektion einer virtuellen NUMA-Topologie in Hyper-V-Virtuelle Maschinen ein. Diese Funktion kann die Leistung von Workloads verbessern, die auf virtuellen Maschinen mit großen Arbeitsspeichern ausgeführt werden. Dynamic Memory in Hyper-V ermöglicht höhere Konsolidierung und verbesserte Neustartzuverlässigkeit, was insbesondere in Umgebungen mit vielen inaktiven oder wenig belasteten VMs, wie VDI-Pools, zu Kostensenkungen führt. Der neue Dynamic Processor Compatibility Mode sorgt dafür, dass die Prozessorfunktionen für VMs auf allen Virtualisierungs-Hosts im Cluster übereinstimmen, indem ein gemeinsames Funktionsset verwendet wird. Jede VM nutzt die maximalen Prozessor-Befehlssätze aller Cluster-Server. GPU-Partitionierung ermöglicht es, eine physische GPU mit mehreren virtuellen Maschinen (VMs) zu teilen. Mit dieser Technik erhält jede VM einen dedizierten Bruchteil der GPU anstelle der gesamten GPU.
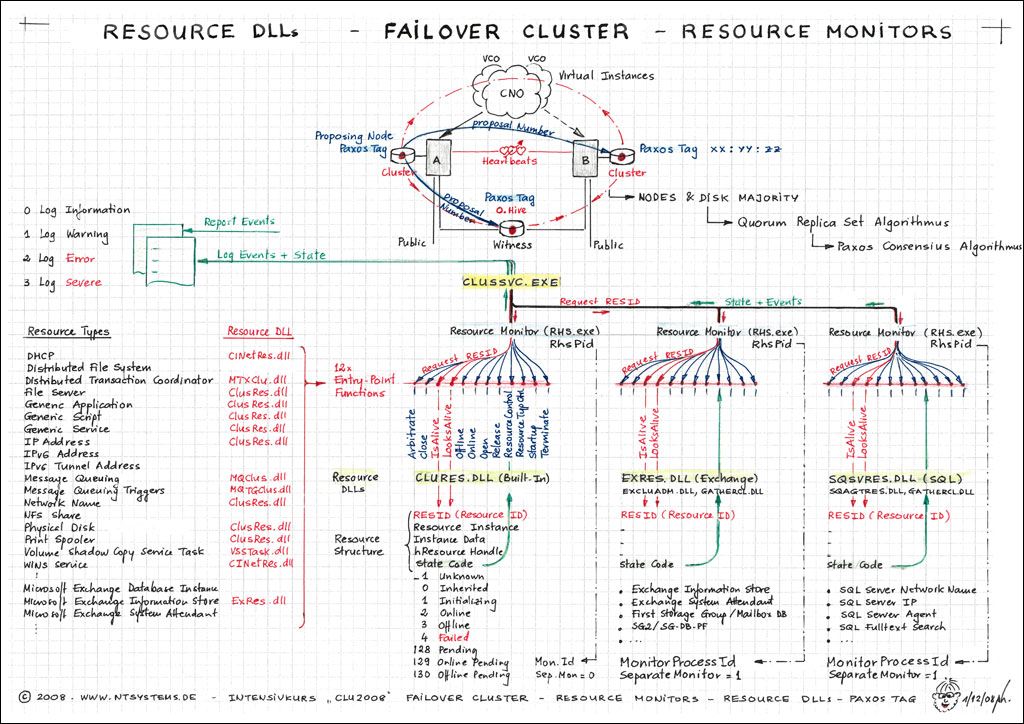
Im Kurs lernen Sie Microsofts Clustertechnologie mit Paxos und dem Quorum Set Replication Algorithmus kennen, der seit 2008 für Distributed Systems verwendet wird. Im Gegensatz zum Single Quorum von Windows 2003 nutzt ein Failover Cluster ab 2008 das neue Hybrid-Quorum nach dem Multimaster-Prinzip. Selbst bei einer defekten Quorum-Disk funktioniert ein 2-Node Cluster stabil weiter. Mit Windows 2012 wurde das Dynamic Quorum eingeführt, das es ermöglicht, dass ein Cluster auch mit nur einem Clusternode arbeitet, solange dieser ordnungsgemäß heruntergefahren wurde. Zudem kann ein Cluster auch mit weniger als 50% Stimmen weiterhin funktionieren. Jeder Clusternode kann mit NodeWeight=0 ausgestattet werden, um ihn von der Quorum-Bildung auszuschließen.